The honest story of adding autonomous remediation to my personal security platform - including all the places it can and will fail. In case you have not read the first post on Nyx, you can do so here
I'm going to be upfront about something: when I started building this feature, I thought it would be simple.
"Scan finds a bug. AI writes the fix. PR gets opened. Done."
That's the mental model I had. Probably three or four hours of work, maybe a weekend at most.
Reader, it was not three or four hours.
The reason it wasn't is that the gap between "AI writes a plausible-looking fix" and "fix is safe enough to put in front of a human reviewer without doing additional damage" is enormous. Bridging that gap is the actual interesting part of Auto PR Mode, so that's mostly what this post is about.
The Problem It's Solving (Which Is Different From What I Thought)
The original pitch I had in my head: scanners find hundreds of vulnerabilities; it's tedious to fix them manually; make the computer do it.
That pitch is fine as far as it goes, but it's solving the wrong problem. The actual bottleneck isn't writing the fix - any reasonably good language model can do that now. At least the ones i have played around with (Gemini and Claude). The bottleneck is trust. You can't ship a fix you haven't verified, and verifying takes time, which means the backlog grows regardless of how fast you can generate patches.
Auto PR Mode doesn't eliminate verification. That would be insane in todays world, maybe one day but that is not this day. What it does is move verification earlier and make it cheaper: instead of a human reading raw scanner output and writing code, a human reads a structured draft PR with the fix pre-written, pre-audited, and pre-tested and decides whether to promote it from draft.
The human is still in the loop. They're just not doing the part that can be automated.
How It Actually Works
The Trigger
A scan completes. The scan worker calls enqueue_auto_pr_findings(), which looks at the repository's configuration: is Auto PR Mode enabled? What severity levels should it target? Is there remaining budget today?
If everything checks out, it queries for all OPEN findings from that scan that match the severity threshold, ordered by priority score (a composite metric Nyx already maintains that factors in CVSS, EPSS, and asset exposure). High priority findings go first.
You can also trigger it manually from the UI, which immediately queues every eligible open finding across the entire repository and not just findings from the latest scan. That's useful when you first enable the mode and have a backlog.
Two Pipelines, Not One
This is the part that surprised me when I thought about it carefully.
Not every finding can be fixed with a code diff. A dependency with a CVE has no line number to patch, not usually anyway. It needs a package version bump, or a switch to a different library, or sometimes a full architectural change. A container image vulnerability might require rebuilding with an updated base image. An exposed secret in environment configuration isn't a diff in the codebase.
I initially wanted to skip these entirely. But that felt like cheating, after all the scanner found them for a reason, and just... ignoring them because they're inconvenient seemed like the wrong answer.
So there are two pipelines:
- Code findings (the finding has a
file_path): generate a diff, audit it, commit it to a branch, open a draft PR. - Advisory findings (no
file_path): generate AI remediation guidance in prose, open a GitHub Issue with that guidance attached, mark it for manual action.
The advisory pipeline is leaner — it uses a smaller model, skips the security audit, and produces a GitHub Issue instead of a PR. It's explicitly not a fix; it's documented evidence that the finding exists, with a written remediation plan the engineer can follow.
The Gates (This Is The Point)
The reason the pipeline is more complicated than "generate fix, open PR" is that it has multiple checkpoints that can each independently block a fix from being committed. I want to be specific about these, because they're not bureaucratic overhead - they're the reason I actually trust the output enough to use it.
Gate 1: Budget. Every repository gets a configurable daily token budget, defaulting to 50,000 tokens. The budget is checked before the pipeline starts, estimated before the fix call, and atomically deducted after each model response. If a fix would push the repository over budget, it doesn't run. The finding gets reopened and will be retried when tomorrow's budget resets. The budget resets daily at 00:05 UTC.
The budget exists because without it, a repository with 200 high-severity findings could consume tens of millions of tokens in a single scan. That's a real cost, and it's yours. Well mine in this case since I spent ~$10 worth of tokens testing this.
Gate 2: Confidence. The fix model (Claude Sonnet) returns a confidence score alongside the diff. If the repository has skip_low_confidence enabled (the default) and the score falls below a threshold, the finding is flagged as REVIEW_LOW_CONFIDENCE and reopened for manual handling. The pipeline never suppresses this signal, if the model isn't sure about the fix, you (the human in the loop) should be the one deciding whether to proceed.
Gate 3: Diff heuristics. Before the fix is audited by the second model, a set of heuristic checks runs over the diff looking for obvious problems: the diff touching files outside the finding's reported path, removals that look like error suppression rather than fixes, patterns that could introduce new attack surface. These are not exhaustive — they're a fast pre-filter that doesn't require an additional model call.
Gate 4: Security audit. This is the one that took the most thought to get right. With the security_audit flag enabled (which it is by default), a second, independent model pass runs after the fix is generated. The audit model: Claude Haiku, which is faster and cheaper for this kind of structured review task, receives the finding metadata and the generated diff, and is asked a specific question: does this fix actually remediate the vulnerability without introducing new ones?
The audit model is prompted to be conservative. When in doubt, fail. If it can't parse the response (the model returns something malformed, the API call times out, anything like that), the default verdict is also failure. Failing closed rather than open. A fix that can't be audited doesn't get committed.
Gate 5: CI checks. If require_passing_checks is enabled, after the draft PR is created, the worker polls the repository's GitHub check runs on the new branch. If they fail, the remediation status flips to TEST_FAILED. If no check runs are found (the repo has no CI on nyx/* branches, which is common), it's treated as a pass rather than a block mainly because silently failing everything for repos without CI would be worse than useless.
The Advisory Pipeline
Let me spend a moment on advisory findings specifically, because I think it's the less obvious half of the feature and also the more honest half.
When a scanner flags a dependency with a known CVE, the correct remediation might be "bump this package from 2.1.3 to 2.1.4," or it might be "this package is abandoned and you need to migrate to a different one," or it might be "this CVE doesn't actually affect your usage pattern." These are different answers that require different responses. A code diff can't express any of them cleanly.
The advisory pipeline handles these findings by generating a structured remediation plan in prose. The AI writes what a senior engineer would write in a ticket: here's the vulnerability, here's what it affects, here's the range of options for addressing it, here's the recommended approach. That gets attached to a GitHub Issue with labels (nyx-advisory, security) so it's discoverable and trackable.
It's not automatic remediation. It's automated triage and documentation. The work still happens in the human's hands. They read the issue, decide on an approach, implement it, close the issue when done. But they're starting from a structured brief rather than a raw scanner alert.
The one thing I deliberately didn't do here is run the security audit on advisory findings. There's no diff to audit. The guidance is prose written for a human to evaluate, not code to commit autonomously. It just wouldn't have made sense.
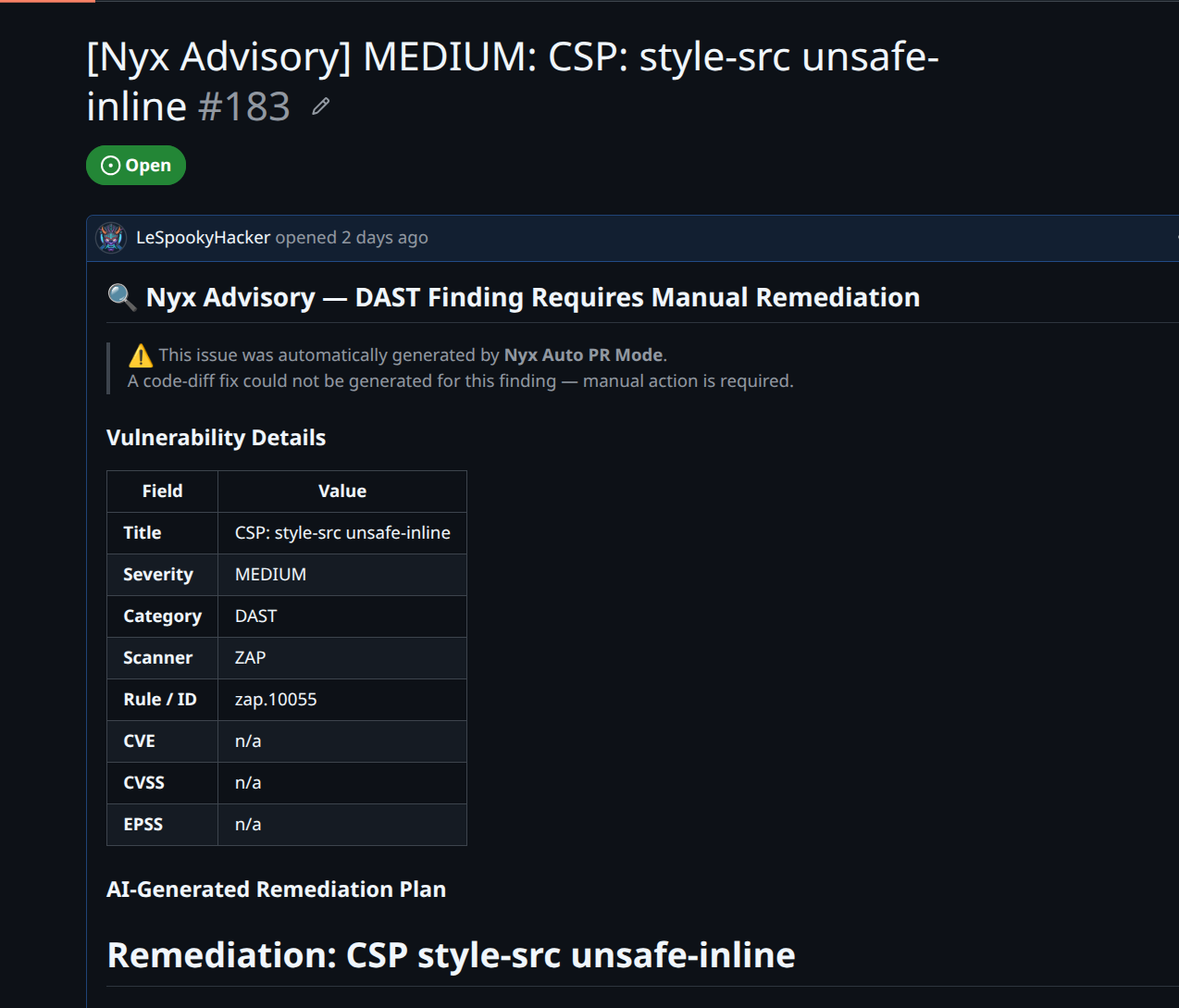
What Gets Built in the Draft PR
Every auto-generated draft PR includes:
- The finding metadata: title, severity, scanner, rule ID, file path and line number, CWE identifiers, CVSS and EPSS scores if available.
- The fix explanation: the model's plain-English description of what it changed and why.
- The audit verdict (if the audit ran): pass/fail, risk level, and the one-paragraph summary from the audit model.
- A prominent notice at the top that this is a draft, it was auto-generated, and it must not be merged until a human verifies it.
The draft state is enforced at the API level — create_fix_pr() always passes draft=True. There's no code path in the worker that promotes a draft to ready-for-review, and there's certainly no merge call. The most the automation does is write the code and open the conversation.
Branch names are always nyx/auto-fix/{first-8-chars-of-finding-id}. They're derived from a server-generated UUID, never from any user-controlled input. This matters because branch names get interpolated into git operations, and I'd rather not hand that to a user-supplied string.
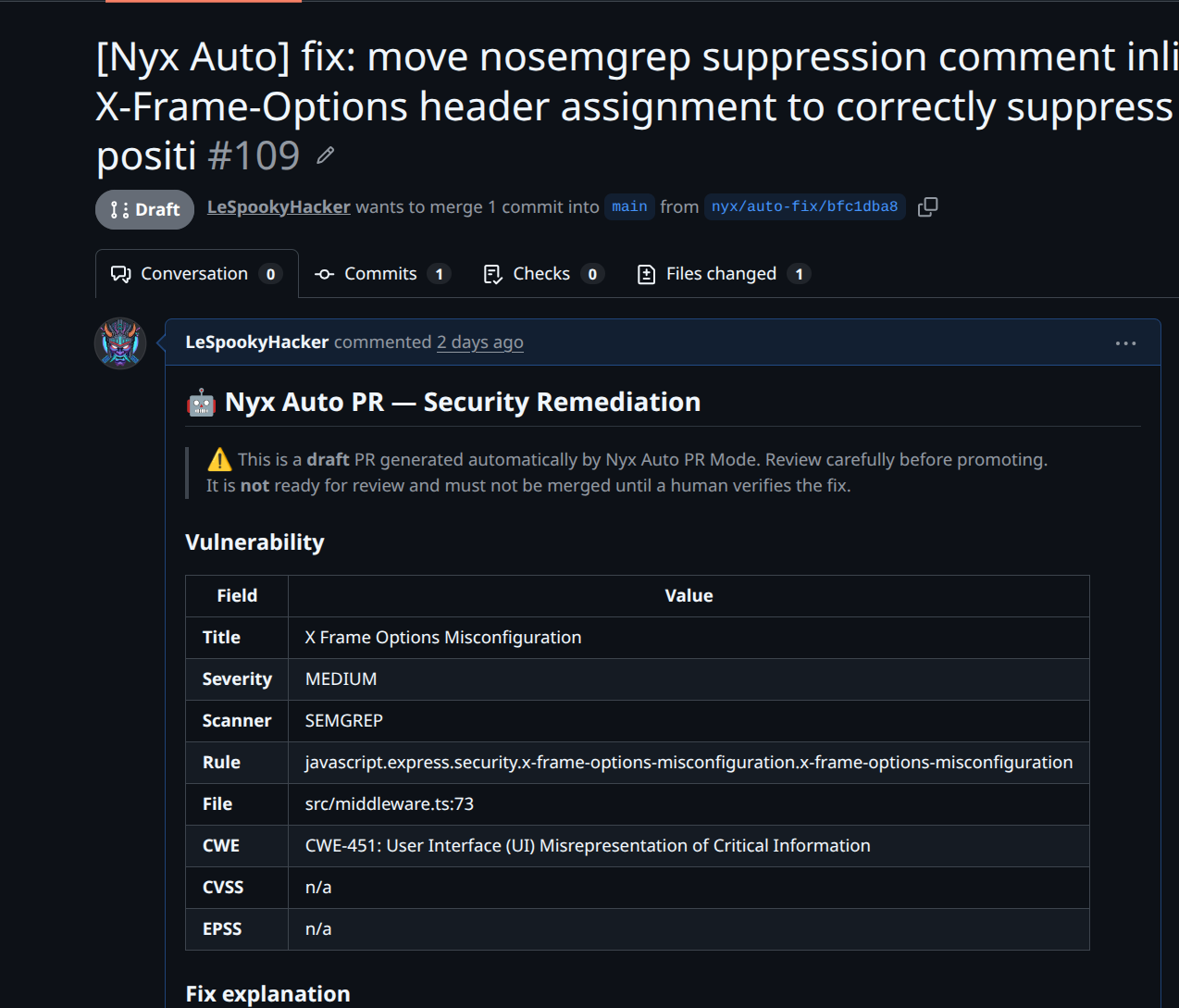
The Self-Healing Mechanism
One thing I learned while testing this is that "eventually consistent state" is not a hypothetical in an async pipeline. It happens. The database commit at the end of _finalize() can fail, where its a connection drop, timeout, whatever. And when it does, the finding stays marked as IN_REMEDIATION with no active worker actually handling it. It's stuck. The next scan comes in, sees the finding is already in remediation, skips it. The finding never gets fixed.
Before processing any new findings, _heal_stuck_findings() runs. It looks for findings in IN_REMEDIATION where every auto-triggered remediation associated with that finding has reached a terminal failure state. If it finds any, it resets them to OPEN. This runs before every trigger, on-demand or post-scan, so a transient DB failure from yesterday doesn't permanently lock a finding out of the pipeline.
It's not elegant. It's the kind of logic you add after something goes wrong in production and you spend an afternoon figuring out why a finding that should have been fixed is just... sitting there.
The Advisory Pipeline: An Illustrated Walk-Through
This is what happens end-to-end for a finding with no patchable file — a dependency CVE, a container image issue, a misconfigured infrastructure component. The output is a GitHub Issue, not a PR. It's the honest version of "we can't fix this for you automatically, but here's the context you need to fix it yourself."
Limitations (Which Are Real)
I'll be direct about these because I want to use this tool myself and I don't benefit from convincing myself it's better than it is.
The AI fix model makes mistakes. Claude Sonnet is good. But it is not infallible. Generated fixes can misunderstand the vulnerability, fix the symptom instead of the root cause, or introduce subtle regressions. The security audit catches a lot of these, but it's also an AI, and AI security audits have their own blind spots. The pipeline is defense in depth, not a guarantee.
The security audit prompt has a scope. The audit model looks for OWASP Top 10 classes of issues in the diff. It does not know your application's full context, your internal security policies, or your threat model. A fix can pass the audit and still be wrong for your specific situation.
CI gate only works if CI is configured for auto branches. The check-run polling works by watching for GitHub Actions runs on the pushed branch. If your repository only runs CI on specific branches or patterns that don't include nyx/*, the gate will see no check runs and treat it as a pass. That's the intended fallback behavior, but it means the CI gate is doing less than you might assume.
Advisory guidance is a starting point, not a solution. The AI-generated remediation plan for a dependency vulnerability is not a substitute for actually reading the CVE, understanding what it affects, and validating that the recommended fix resolves it in your environment.
The daily token budget is per-repository and resets at midnight UTC. If you have many repositories with Auto PR Mode enabled, the budgets don't pool or share. Each repository is isolated. This is intentional — cost is predictable per-repo — but worth knowing for your planning capacity.
Configuration
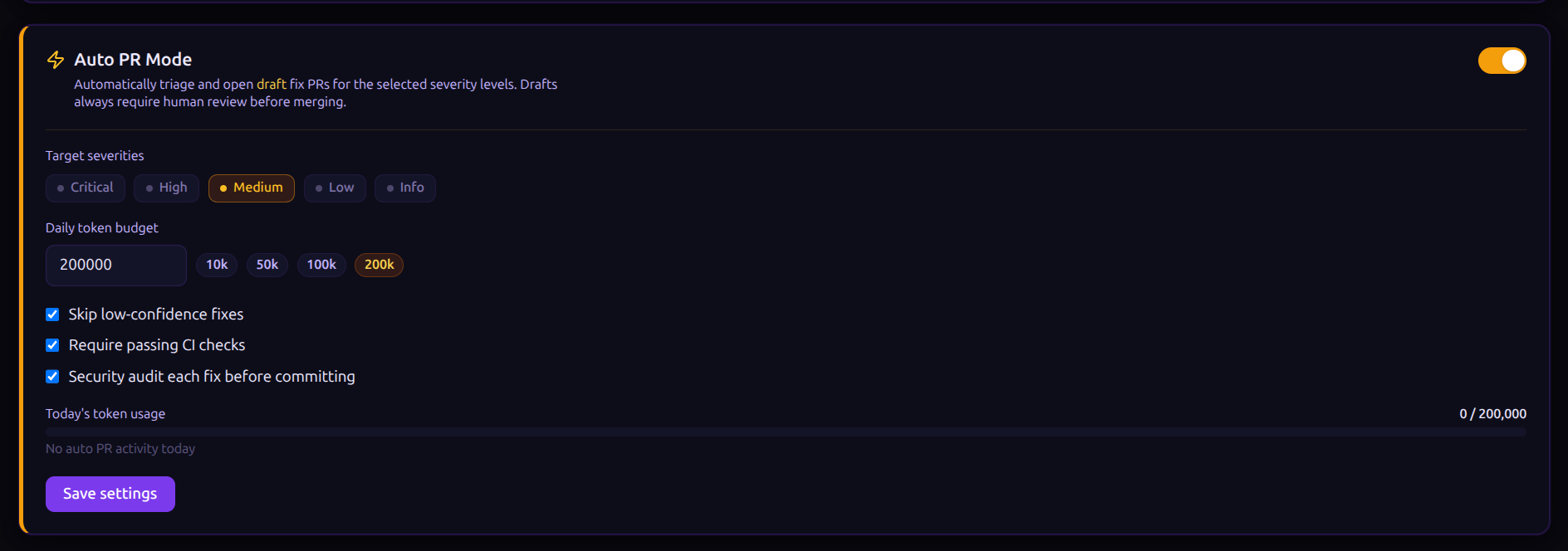
All of this is configurable per repository from the UI. The settings that matter:
- Severity threshold: which finding severities to act on. Defaults to CRITICAL and HIGH. You can extend it down to MEDIUM, LOW, or INFO if you want, but I'd recommend starting conservative.
- Daily token budget: how many tokens the pipeline is allowed to spend per day across all findings in that repository. Default is 50,000. A single complex fix costs roughly 2,000–8,000 tokens depending on file size.
- Skip low-confidence fixes: whether to halt when the fix model flags low confidence. Default on. Turning this off means you'll see more fixes committed as drafts, some of which will be obviously wrong.
- Require passing CI checks: whether to block on a failed check run after the PR is created. Default on, but only useful if CI is configured to run on
nyx/*branches.
- Security audit: whether to run the second-model audit pass before committing. Default on. Turning this off removes one of the stronger safety guarantees and I'd recommend against it unless you're debugging or running in a very cost-constrained environment.
There's also a global configuration flag (AUTO_PR_MODE_ENABLED) in the platform settings. Even with that enabled, Auto PR Mode is opt-in per repository — you have to explicitly toggle it on for each repo, confirm the settings in a modal, and the first run immediately queues whatever eligible findings exist. There's no passive enrollment.
Why I Built It This Way
The temptation with autonomous code generation is to make it do as much as possible. Merge the PR automatically, skip the audit if it's too slow, extend to lower severity findings to cover more surface area.
I resisted all of those. Not out of excessive caution, but because the marginal value of each cut corner is small and the marginal risk is not.
A merged PR that introduces a new vulnerability is worse than no PR at all. An unaudited fix that looks right but isn't creates a false sense of progress. Extending to INFO-severity findings means spending real resources on noise.
The design goal was: generate work that makes a human's review session faster and more confident, without creating new work they have to undo. Draft PRs, hard budget limits, double-model review, conservative defaults. If it's not sure, it stops and lets you decide.
Is it more conservative than it could be? Yes. Is it more useful because of that? Also yes.
What's Next
A few things I'm thinking about:
- PR enrichment: attaching more structured context to the draft PR — affected test coverage, similar past fixes, whether the vulnerability class has been seen before in this repo.
- Cross-finding deduplication: if the same root cause produces multiple related findings, it might make sense to batch them into a single PR rather than generating N separate branches.
- Configurable audit model: right now the audit always uses Haiku. For higher-severity findings, I might want to optionally route to a stronger model.
- Advisory issue resolution tracking: closing the advisory issue when the related scan finding is resolved, rather than relying on the engineer to remember to close it manually.
None of these change the fundamental design though. Human in the loop, draft only, fail closed. They're refinements to the output quality and feedback loops.
If you've read this far, you have a reasonable picture of what the feature actually does and where it makes tradeoffs. It's not magic. It's a pipeline with guardrails that tries to do useful automation without removing human judgment from the places where human judgment matters.
The code is on the feat/auto-pr-mode branch if you want to dig into the implementation directly. But by the time this is published it will most likely be merged to main. The worker is backend/app/workers/auto_pr_worker.py and the audit service is backend/app/services/auto_pr_audit_service.py.
Be sure to check out the code here: https://github.com/LeSpookyHacker/nyx
Nyx is a personal security platform I built and use for my own projects. It has rough edges, known bugs, and is not a polished enterprise product.
Join the Grimoire
Get notified when I publish new posts. No spam, unsubscribe anytime.